Tuesday, January 31, 2006
Flashback Database (how-to)
Antes de mais nada, se for seguir esse HOW-TO! Por favor, faça um BACKUP do banco.
Para habilitar a Flash Recovery Area.
É necessário setar os parâmetros db_recovery_file_dest e db_recovery_file_dest_size. O size primeiro senão leva o seguinte erro:
Exemplo - v$recovery_file_dest.
Habilitar o banco para flashback logging.
Para habilitar a Flash Recovery Area.
É necessário setar os parâmetros db_recovery_file_dest e db_recovery_file_dest_size. O size primeiro senão leva o seguinte erro:
SQL> alter system set db_recovery_file_dest = '/dsk1/app/FRA' scope=both;Portanto, devemos setar o db_recovery_file_dest_size, depois o caminho do disco.
alter system set db_recovery_file_dest = '/dsk1/app/FRA' scope=both
*
ERROR at line 1:
ORA-02097: parameter cannot be modified because specified value is invalid
ORA-19802: cannot use DB_RECOVERY_FILE_DEST without DB_RECOVERY_FILE_DEST_SIZE
SQL> alter system set db_recovery_file_dest_size = 6g scope=both;Flash Recovery Area - setado! Uma pausa para conceituar o que é Flash Recovery Area: No 10g a Oracle pensou em uma forma de monitorar um repositório de arquivos. É uma forma de centralizar os arquivos de recuperação (backups). A monitoração é feita através do EM (Enterprise Manager) ou das views dinâmicas.
System altered.
SQL> alter system set db_recovery_file_dest = '/dsk1/app/FRA' scope=both;
System altered.
Exemplo - v$recovery_file_dest.
Próximo passo, enviar meus archives para Flash Recovery Area.
SQL> select name, space_limit as quota,
2 space_used as used,
3 space_reclaimable as reclaimable,
4 number_of_files as files
5 from v$recovery_file_dest
SQL> /
NAME QUOTA USED RECLAIMABLE FILES
------------------------------ ------------- ------------- ------------- -------------
/dsk1/app/FRA 6442450944 2715843072 0 73
1 row selected.
SQL> alter system set log_archive_dest_1 = 'LOCATION=USE_DB_RECOVERY_FILE_DEST' scope=both;Assim como na área de UNDO temos um tempo de retenção para as transações, no flashback de database é preciso marcar um tempo para que o banco guarde informações necessárias para eventual recuperação. O parâmetro é:
System altered.
SQL> show parameter flashPortanto, retenção da flashback logging de 24 horas. Tempo em minutos. 24*60 = 1440.
NAME TYPE VALUE
------------------------------------ ----------- ----------------------------------------
db_flashback_retention_target integer 1440
Habilitar o banco para flashback logging.
SQL> connect / as sysdbaOps! É manutenção! O banco deve estar montado somente e logo depois devemos fazer backup.
Connected.
SQL> select flashback_on from v$database;
FLASHBACK_ON
------------------
NO
1 row selected.
SQL>
SQL> alter database flashback on;
alter database flashback on
*
ERROR at line 1:
ORA-38759: Database must be mounted by only one instance and not open.
SQL> shutdown immediateSeu banco está pronto para flashback.
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> startup mount
ORACLE instance started.
Total System Global Area 285212672 bytes
Fixed Size 1218968 bytes
Variable Size 109053544 bytes
Database Buffers 167772160 bytes
Redo Buffers 7168000 bytes
Database mounted.
SQL> alter database flashback on;
Database altered.
SQL> alter database open;
Database altered.
SQL> select flashback_on from v$database;
FLASHBACK_ON
------------------
YES
1 row selected.
Labels: how to
Friday, January 20, 2006
Evitando GAPS em sistemas
Alguns sistemas não têm jeito! Necessitam de número seqüencial para alguns de seus campos. Seja nota fiscal, pedidos, enfim, são vários os exemplos. Para este tipo de sistema o analista NÃO DEVE CONSIDERAR sequence do Oracle. Veja que mesmo o manual aconselha isso:
Fato!
Precisamos de números livres de gaps.
Como fazer?
O que é preciso considerar e lidar, é a serialização no momento de ¨pegar¨ um número, o sistema colocará um semáforo (lock) e permitirá somente um acesso de cada vez.
Pense na serialização como algo parecido com banheiro de posto de gasolina, onde a chave fica no caixa, ou seja, vai um de cada vez. Se sua aplicação é aquele posto pouco freqüentado, tudo bem, quase nunca haverá fila; agora se seu posto for aquele do momento (bombando mesmo) - imagine o desconforto de enfrentar uma fila! Por isso o desenho da aplicação deve considerar performance.
Então como você faria?
Criaria uma tabela IOT com a descrição do ID necessário e manteria ali o último registro. Concluindo com uma função, onde buscaria o descrição do id e devolveria o número seqüencial livre de gaps. Ainda que ocorra GAP é possível "ajustar" essa tabela facilmente.
Caution: If your application can never lose sequence numbers, then you cannot use Oracle sequences, and you may choose to store sequence numbers in database tables. Be careful when implementing sequence generators using database tables. Even in a single instance configuration, for a high rate of sequence values generation, a performance overhead is associated with the cost of locking the row that stores the sequence value.
Fato!
Precisamos de números livres de gaps.
Como fazer?
O que é preciso considerar e lidar, é a serialização no momento de ¨pegar¨ um número, o sistema colocará um semáforo (lock) e permitirá somente um acesso de cada vez.
Pense na serialização como algo parecido com banheiro de posto de gasolina, onde a chave fica no caixa, ou seja, vai um de cada vez. Se sua aplicação é aquele posto pouco freqüentado, tudo bem, quase nunca haverá fila; agora se seu posto for aquele do momento (bombando mesmo) - imagine o desconforto de enfrentar uma fila! Por isso o desenho da aplicação deve considerar performance.
Então como você faria?
Criaria uma tabela IOT com a descrição do ID necessário e manteria ali o último registro. Concluindo com uma função, onde buscaria o descrição do id e devolveria o número seqüencial livre de gaps. Ainda que ocorra GAP é possível "ajustar" essa tabela facilmente.
SQL> create table
2 ids (
3 name varchar2(30) constraint ids_pk primary key,
4 id number
5 ) organization index
6 ;
Table created.
SQL>
SQL> create or replace
2 function get_nextval( p_name in varchar2 ) return number
3 is
4 l_id number;
5 begin
6 update ids set id = id+1
7 where name = upper(p_name)
8 returning id into l_id;
9
10 if ( sql%rowcount = 0 )
11 then
12 raise_application_error( -20001,
13 'Nao existe id para ' || p_name);
14 end if;
15 return l_id;
16 end;
17 /
Function created.
SQL>
SQL> var n number
SQL> exec :n := get_nextval('NF')
BEGIN :n := get_nextval('NF'); END;
*
ERROR at line 1:
ORA-20001: Nao existe id para NF
ORA-06512: at "OPS$MARCIO.GET_NEXTVAL", line 11
ORA-06512: at line 1
N
-------------
SQL> insert into ids values ('NF', 0 );
1 row created.
SQL> exec :n := get_nextval('NF')
PL/SQL procedure successfully completed.
N
-------------
1
Labels: how to
Tuesday, January 17, 2006
Como Encontrar Gaps em uma Sequência?
Os desenvolvedores usam uma sequence para preencher a pk de uma tabela, só que alguém andou com a sequence em alguns momentos e a pk da tabela, que tem que ser sequencial, ficou com furos, exemplo :
protocolo_inscricao
1
3
4
5
6
10
13
Há alguma função que me diga quais os números estão faltando porque foram pulados pelo avanço indevido da sequence ?
Exitem outros métodos, mas o que eu escolhi para apresentar foi o seguinte: gerar uma "baseline" com todos os números em sequência. Procurei gerar essa tabela de forma mais leve possível - através da tabela dual. Podemos gerar milhões (literalmente) com pouco esforço.
A partir desta tabela completa, basta entrelaçar com a sequência quebrada ou seja a diferença do conjunto completo pelo quebrado.
Veja na figura como identificar os gaps. Na primeira coluna teremos o conjunto sequencial completo, na segunda o quebrado e a zona cinza os gaps.
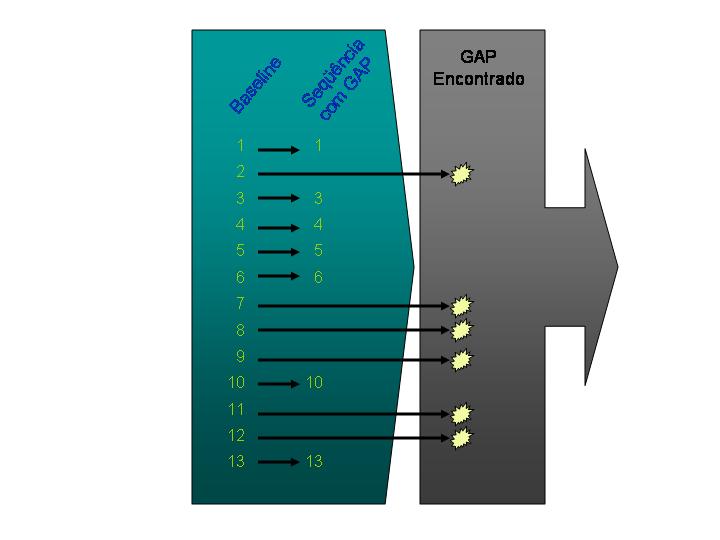
Como se pode notar, o conjunto dos gaps é formado pelos números { 2, 7, 8, 9, 11, 12 }
Prova!
Como chegar a esse resultado? Com a figura e as afirmações:
a) entrelaçar a tabela completa com a sequência quebrada ( OUTER JOIN )
b) diferença do conjunto completo pelo quebrado ( MINUS )
Basta:
a)
SQL> with seq as (
2 select level l
3 from dual connect by level <= ( select max(x) from t )
4 )
5 select l, x, decode(x, null, l ) falta
6 from seq left outer join t on ( l = x )
7 order by 1
8 /
L X FALTA
------------- ------------- -------------
1 1
2 2
3 3
4 4
5 5
6 6
7 7
8 8
9 9
10 10
11 11
12 12
13 13
13 rows selected.
b)
SQL> with seq as (
2 select level l
3 from dual connect by level <= ( select max(x) from t )
4 )
5 select * from seq
6 minus
7 select * from t
8 /
L
-------------
2
7
8
9
11
12
6 rows selected.
Labels: how to
Friday, January 13, 2006
Escrevendo (código) Demais
Resolvi escrever esta nota, não para criticar os desenvolvedores que gostam de codificar de tudo, mas alertar que quanto mais simples e comentado deixamos o código, melhor será nossa vida no futuro - e tomando emprestado o ditado: "quem fala demais dá bom-dia a cavalo", escrever código desnecessariamente também não é uma boa idéia.
Dias atrás, estava navegando através dos forums e me deparei com uma dúvida relacionada ao código abaixo. Não me lembro da dúvida, porque a primeira coisa que eu faço quando leio uma, é otimizar a semântica, não a sintaxe, portanto tento entender o que a pessoa pretende, para ajudá-la.
Neste caso, nosso herói queria escrever uma função para converter data Gregoriana em data Juliana (número de dias desde as 12:00 de 1 de janeiro de 4713 aC). Ora, de primeira minha resposta foi: por que está codificando algo que já existe? Se o TO_CHAR( date, 'J' ) faz isso! Mas o pior foi constatar que a função estava errada!
Me Mostra?
No código, eu retirei os comentários para evitar identificação. Não estou preocupado em apontar o dedo à ninguém e sim alertar para: primeiro procurar esgotar as possibilidades que o built-in oferece. Além de já estar pronto e testado, preserva o código como legado em migrações futuras.
Eis a função.
Substituindo agora para reverter de juliana para gregoriana. Aqui é a prova dos nove.
Agora sim, podemos ver nitidamente que o valor obtido pela função TO_JULIANA (vermelho) não está nem de perto correto. Neste caso, a função seria:
Dias atrás, estava navegando através dos forums e me deparei com uma dúvida relacionada ao código abaixo. Não me lembro da dúvida, porque a primeira coisa que eu faço quando leio uma, é otimizar a semântica, não a sintaxe, portanto tento entender o que a pessoa pretende, para ajudá-la.
Neste caso, nosso herói queria escrever uma função para converter data Gregoriana em data Juliana (número de dias desde as 12:00 de 1 de janeiro de 4713 aC). Ora, de primeira minha resposta foi: por que está codificando algo que já existe? Se o TO_CHAR( date, 'J' ) faz isso! Mas o pior foi constatar que a função estava errada!
Me Mostra?
No código, eu retirei os comentários para evitar identificação. Não estou preocupado em apontar o dedo à ninguém e sim alertar para: primeiro procurar esgotar as possibilidades que o built-in oferece. Além de já estar pronto e testado, preserva o código como legado em migrações futuras.
Eis a função.
CREATE OR REPLACE Function to_juliana (dt_a_converter DATE )
RETURN NUMBER IS
dt_juliana NUMBER;
BEGIN
/* ------ -- ------- -- --------- ---- ---- ------- */
dt_juliana := 0;
dt_juliana := To_Char( TO_DATE( dt_a_converter ) , 'YYYYDDD') - 1900000 ;
/* ---------- - ------- -- ------ */
RETURN( dt_juliana );
END To_Juliana;
/
ops$marcio@LNX10GR2>
ops$marcio@LNX10GR2> CREATE OR REPLACE Function to_juliana (dt_a_converter DATE )
2 RETURN NUMBER IS
3 dt_juliana NUMBER;
4
5 BEGIN
6 /* ------ -- ------- -- --------- ---- ---- ------- */
7
8 dt_juliana := 0;
9 dt_juliana := To_Char( TO_DATE( dt_a_converter ) , 'YYYYDDD') - 1900000 ;
10
11 /* ---------- - ------- -- ------ */
12 RETURN( dt_juliana );
13 END To_Juliana;
14 /
Function created.
ops$marcio@LNX10GR2> select to_juliana(sysdate) x,
2 to_number(to_char(sysdate, 'j')) y
3 from dual
4 /
X Y
------------- -------------
106013 2453749
1 row selected.
Substituindo agora para reverter de juliana para gregoriana. Aqui é a prova dos nove.
ops$marcio@LNX10GR2> select to_date( 106013, 'j') feito,
2 to_date( 2453749, 'j') builtin
3 from dual
4 /
FEITO BUILTIN
------------------- -------------------
01/04/4422 00:00:00 13/01/2006 00:00:00
1 row selected.
Agora sim, podemos ver nitidamente que o valor obtido pela função TO_JULIANA (vermelho) não está nem de perto correto. Neste caso, a função seria:
create or replace
function to_juliana ( p_date in date ) return number
is
begin
return to_number(to_char(p_date, 'j'));
end;
/
ops$marcio@LNX10GR2> select to_juliana( sysdate ) from dual;
TO_JULIANA(SYSDATE)
-------------------
2453749
1 row selected.
ops$marcio@LNX10GR2> select to_date( 2453749, 'j' ) from dual;
TO_DATE(2453749,'J'
-------------------
13/01/2006 00:00:00
1 row selected.
Thursday, January 12, 2006
Trigger AFTER SERVERERROR
Tenho uma trigger AFTER SERVERERROR na qual grava, em uma tabela de log, todos os erros que ocorrem no banco de um determinado usuário.
Como eu conseguiria, de dentro da trigger, capturar o comando que acarretou determinado erro (que fez disparar a trigger), para nesta tabela de log eu ter o comando disparado e os erros ocorridos?
ops$marcio@LNX10GR2> create table
2 log (
3 dt date,
4 usr varchar2(30),
5 stmt varchar2(4000)
6 );
Table created.
ops$marcio@LNX10GR2>
ops$marcio@LNX10GR2> create or replace trigger catch_error
2 after servererror on database
3 declare
4 l_text ora_name_list_t;
5 l_n number;
6 l_stmt varchar2(4000);
7 begin
8 l_n := ora_sql_txt( l_text );
9
10 for i in 1 .. nvl(l_text.count,0)
11 loop
12 l_stmt := l_text(i);
13 end loop;
14
15 l_stmt := l_stmt || '=> ';
16
17 for i in 1 .. ora_server_error_depth
18 loop
19 l_stmt := l_stmt || ora_server_error_msg(i);
20 end loop;
21
22 insert into log values ( sysdate, user, l_stmt );
23 end;
24 /
Trigger created.
ops$marcio@LNX10GR2> show error
No errors.
ops$marcio@LNX10GR2>
ops$marcio@LNX10GR2> drop table x;
drop table x
*
ERROR at line 1:
ORA-00942: table or view does not exist
ops$marcio@LNX10GR2>
ops$marcio@LNX10GR2> connect scott/tiger
Connected.
scott@LNX10GR2>
scott@LNX10GR2> select * from sys.aud$;
select * from sys.aud$
*
ERROR at line 1:
ORA-00942: table or view does not exist
scott@LNX10GR2>
scott@LNX10GR2> connect /
Connected.
ops$marcio@LNX10GR2>
ops$marcio@LNX10GR2> select * from log;
DT USR STMT
------------------- ------------- ----------------------------------------------------------------------
12/01/2006 01:59:13 SCOTT select * from sys.aud$ => ORA-00942: table or view does not exist
12/01/2006 01:59:13 OPS$MARCIO drop table x => ORA-00942: table or view does not exist
2 rows selected.
Labels: how to
Tuesday, January 10, 2006
PIVOT
Uma técnica comum em SQL é o Pivot. Algumas vezes temos necessidade de apresentar relatórios por grupo, por exemplo o cliente possui alguns telefones de contato, mas eles estão em registros diferentes ao longo da tabela, por que no desenho, cada registro do telefone mostra se o número é residência, celular ou comercial (tipo 1, 2 ou 3).
Exemplo!
Primeiro os dados - T é a tabela onde estão os telefones, nm_tel número e tipo_fone classificação em residência, celular ou comercial.
Como podemos notar, temos 4 clientes diferentes e, em nosso exemplo o número de telefones diferentes por cliente é razoável para fazermos um pivot em sql puro, em outra oportunidade, mostrarei um pivot genérico usando pl/sql.
De volta ao exemplo, para saber quantas colunas devemos distribuir os números de telefone por cliente, pegamos o maior valor da quantidade de telefones por cliente.
3 (três), portanto. Com essa informação, montamos nosso pivot para apresentar o cliente e seus respectivos telefones - tudo em uma linho só. O uso do max() é um truque para que seu result set não vire uma "escada" (para ver o efeito escada, basta retirar o max da query).
Exemplo!
Primeiro os dados - T é a tabela onde estão os telefones, nm_tel número e tipo_fone classificação em residência, celular ou comercial.
SQL> select * from t;
COD_CLIENTE NM_TEL TIPO_FONE
------------- ------------- -------------
5 50832590 1
5 55727019 2
6 62856486 1
6 97465225 2
6 36676744 2
7 65214314 1
7 99042269 1
8 69528914 3
8 91252514 1
9 rows selected.
Como podemos notar, temos 4 clientes diferentes e, em nosso exemplo o número de telefones diferentes por cliente é razoável para fazermos um pivot em sql puro, em outra oportunidade, mostrarei um pivot genérico usando pl/sql.
De volta ao exemplo, para saber quantas colunas devemos distribuir os números de telefone por cliente, pegamos o maior valor da quantidade de telefones por cliente.
SQL>
SQL> select max(cnt)
2 from ( select cod_cliente, count(*) cnt
3 from t
4 group by cod_cliente )
5 /
MAX(CNT)
-------------
3
1 row selected.
3 (três), portanto. Com essa informação, montamos nosso pivot para apresentar o cliente e seus respectivos telefones - tudo em uma linho só. O uso do max() é um truque para que seu result set não vire uma "escada" (para ver o efeito escada, basta retirar o max da query).
SQL>
SQL> select cod_cliente,
2 max(decode(rn, 1, nm_tel, null)) nm_tel1,
3 max(decode(rn, 2, nm_tel, null)) nm_tel2,
4 max(decode(rn, 3, nm_tel, null)) nm_tel3
5 from (
6 select cod_cliente, nm_tel,
7 row_number() over (partition by cod_cliente
8 order by cod_cliente ) rn
9 from t
10 )
11 group by cod_cliente
12 /
COD_CLIENTE NM_TEL1 NM_TEL2 NM_TEL3
------------- ------------- ------------- -------------
5 55727019 50832590
6 97465225 62856486 36676744
7 65214314 99042269
8 69528914 91252514
4 rows selected.
Labels: how to
Monday, January 09, 2006
ROLLUP
As vezes esquecemos como pode ser simples uma query através das opções disponíveis. O rollup, por exemplo, é uma clausula ainda pouco explorado, embora seja extremamente útil para sumarizações e acima de tudo é performática.
Quero ver!
Na tabela emp, queremos saber o total pago em salários por job, deptno e gran total em um mesmo relatório.
Poderíamos começar com:
Seria um método. Agora, qual o custo disso? Ahh, eu fiz 3 tablescan contra a tabela emp para: primeiro conseguir o total por job, depois para conseguir o total por deptno e finalmente o "Gran Total". Vejam o custo.
Sem entrar muito em hash/sort, o resumo foi 3 full table scan em EMP com 9 consistent gets para chegar ao result set. Agora vamos usar o ROLLUP.
Além de ser mais entendível semanticamente, a performance não se compara. O custo do mesmo resultado é de 1/3 se compararmos com o custo da primeira execução, desta vez o Oracle precisou somente de 1 full e 3 consistent gets para compor o MESMO result set.
A conclusão que devemos ter em conta a partir deste pequeno exemplo é procurar entender e aprender os recursos que a ferramenta oference, não importa se Oracle, SQL Server, MySQL, Windows, Linux, VMS, etc - Todos os dias procure conhecer algo novo da ferramente velha.
Quero ver!
Na tabela emp, queremos saber o total pago em salários por job, deptno e gran total em um mesmo relatório.
Poderíamos começar com:
SQL> col deptno format a10
SQL> break on deptno skip 2
SQL>
SQL> select *
2 from (
3 select to_char(deptno) deptno, job, sum(sal)
4 from emp
5 group by deptno, job
6 union all
7 select to_char(deptno) deptno, 'Total....' job, sum(sal)
8 from emp
9 group by deptno
10 union all
11 select 'Gran' deptno, 'Total....' job, sum(sal)
12 from emp
13 )
14 order by 1, job
15 /
DEPTNO JOB SUM(SAL)
---------- --------- -------------
10 CLERK 1300
MANAGER 2450
PRESIDENT 5000
Total.... 8750
20 ANALYST 6000
CLERK 1900
MANAGER 2975
Total.... 10875
30 CLERK 950
MANAGER 2850
SALESMAN 5600
Total.... 9400
Gran Total.... 29025
13 rows selected.
Seria um método. Agora, qual o custo disso? Ahh, eu fiz 3 tablescan contra a tabela emp para: primeiro conseguir o total por job, depois para conseguir o total por deptno e finalmente o "Gran Total". Vejam o custo.
------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 15 | 615 | 12 (25)| 00:00:01 |
| 1 | SORT ORDER BY | | 15 | 615 | 12 (25)| 00:00:01 |
| 2 | VIEW | | 15 | 615 | 11 (19)| 00:00:01 |
| 3 | UNION-ALL | | | | | |
| 4 | HASH GROUP BY | | 11 | 165 | 4 (25)| 00:00:01 |
| 5 | TABLE ACCESS FULL| EMP | 14 | 210 | 3 (0)| 00:00:01 |
| 6 | HASH GROUP BY | | 3 | 21 | 4 (25)| 00:00:01 |
| 7 | TABLE ACCESS FULL| EMP | 14 | 98 | 3 (0)| 00:00:01 |
| 8 | SORT AGGREGATE | | 1 | 4 | | |
| 9 | TABLE ACCESS FULL| EMP | 14 | 56 | 3 (0)| 00:00:01 |
------------------------------------------------------------------------------
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
9 consistent gets
0 physical reads
0 redo size
769 bytes sent via SQL*Net to client
385 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
13 rows processed
Sem entrar muito em hash/sort, o resumo foi 3 full table scan em EMP com 9 consistent gets para chegar ao result set. Agora vamos usar o ROLLUP.
SQL> select nvl(to_char(deptno), 'Gran') deptno,
2 nvl(job, rpad('Total',9,'.')) job,
3 sum(sal)
4 from emp
5 group by rollup(deptno, job)
6 /
DEPTNO JOB SUM(SAL)
---------- --------- -------------
10 CLERK 1300
MANAGER 2450
PRESIDENT 5000
Total.... 8750
20 CLERK 1900
ANALYST 6000
MANAGER 2975
Total.... 10875
30 CLERK 950
MANAGER 2850
SALESMAN 5600
Total.... 9400
Gran Total.... 29025
13 rows selected.
Além de ser mais entendível semanticamente, a performance não se compara. O custo do mesmo resultado é de 1/3 se compararmos com o custo da primeira execução, desta vez o Oracle precisou somente de 1 full e 3 consistent gets para compor o MESMO result set.
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 11 | 165 | 4 (25)| 00:00:01 |
| 1 | SORT GROUP BY ROLLUP| | 11 | 165 | 4 (25)| 00:00:01 |
| 2 | TABLE ACCESS FULL | EMP | 14 | 210 | 3 (0)| 00:00:01 |
-----------------------------------------------------------------------------
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
3 consistent gets
0 physical reads
0 redo size
769 bytes sent via SQL*Net to client
385 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
13 rows processed
A conclusão que devemos ter em conta a partir deste pequeno exemplo é procurar entender e aprender os recursos que a ferramenta oference, não importa se Oracle, SQL Server, MySQL, Windows, Linux, VMS, etc - Todos os dias procure conhecer algo novo da ferramente velha.
Labels: how to
Thursday, January 05, 2006
A Arte da Performance
Performance
Como falar sobre performance? Por que eu sou um paranóico por ela? Etimologicamente, performance vem do Francês antigo: par + fournir, ou seja, enfeitar, decorar, fornecer, persistir em uma tarefa até que seja completa. Anos depois, ficou conhecida como dar show, apresentação em um palco, afinação, além disso, atualmente significa desempenho juntando todas as definições anteriores. Então, se seu código tem performance, ele literalmente dá show. É isso que os usuários esperam: que seu código seja um espetáculo.
Eu realmente penso muito no desempenho dos sistemas que desenvolvo. Isso determina o sucesso ou o fracasso deles. Não importa qual tecnologia, quantas camadas, linguagem de desenvolvimento ou banco de dados, se aplicativo, interface ou seja lá o que estiver fazendo, não executar de acordo ao que o negócio exige, estará fadado ao fracasso.
Quem determina o quão rápido o sistema deve ser é o negócio para qual ele será desenvolvido. Por exemplo, em uma aplicação bancária, onde o cliente vai sacar dinheiro, o tempo de operação deve ser menor que 10 segundos após o cliente confirmar a senha. Esse é o requisito para a operação. Entretanto, se o sistema é um fechamento contábil, a operação de fechamento talvez possa esperar 15 minutos por filial.
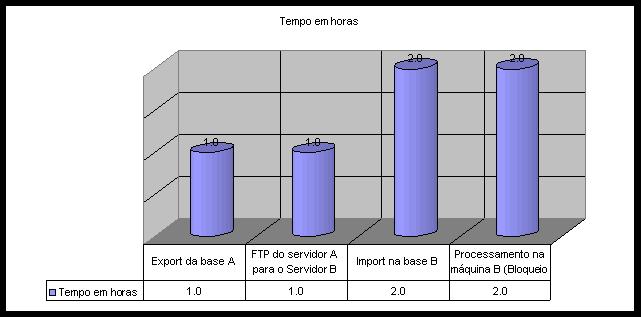
Certa ocasião, fui chamado para otimizar um sistema em uma concessionária de telecomunicações. O processo batch para bloqueio de terminais pré-pagos estava executando em uma janela de 6 horas. O cliente estava com problemas jurídicos, porque alguns terminais já pagos, eram desbloqueados somente após de 48 horas do pagamento do mesmo. Quando a tarefa do banco de dados foi atribuída a mim, procurei entender o que o processo estava fazendo. Encontrei mais ou menos como segue a tabela/gráfico abaixo:

Podemos notar um overhead de no mínimo 4 horas no processo – MÍNIMO – por que? Ora, se estou na mesma rede, mesma empresa, por que tenho que fazer FTP de um lado para outro? Por que tenho que fazer EXPORT de uma base e IMPORT na outra? Encontrei as respostas facilmente quando investiguei um pouco a origem do sistema. Nenhum analista de banco de dados do lado da nossa empresa, tampouco o DBA da concessionária fora consultado.
Tiradas essas conclusões, armei um plano para desenvolver uma pequena API usando DBLINK, evitando o EXPORT – FTP – IMPORT, ou seja, 4 horas somente em processos desnecessários. Entrei em contato com o DBA deles, acertamos o DBLINK e as permissões necessárias e depois reescrevi o código para desbloqueio a cada N horas conforme o operador determinava; deixei o sistema bastante flexível quanto à execução. Cada vez que o processo “acorda” executava em menos de um minuto e alimentava o MAINFRAME para designar o desbloqueio no mesmo dia. Na verdade, a grande sacada aqui foi: 75% do tempo era gasto em overhead. O que fiz? Me livrei dos processos. Negociei com o DBA para evitarmos esse desperdício. Isso nos rendeu um elegante e-mail de elogios.
Para Performance não existe uma receita de bolo, é preciso usar a criatividade encontrando alternativas. O que é certo é que seu sistema precisa dar SHOW! Precisa de performance SEMPRE.
Como falar sobre performance? Por que eu sou um paranóico por ela? Etimologicamente, performance vem do Francês antigo: par + fournir, ou seja, enfeitar, decorar, fornecer, persistir em uma tarefa até que seja completa. Anos depois, ficou conhecida como dar show, apresentação em um palco, afinação, além disso, atualmente significa desempenho juntando todas as definições anteriores. Então, se seu código tem performance, ele literalmente dá show. É isso que os usuários esperam: que seu código seja um espetáculo.
Eu realmente penso muito no desempenho dos sistemas que desenvolvo. Isso determina o sucesso ou o fracasso deles. Não importa qual tecnologia, quantas camadas, linguagem de desenvolvimento ou banco de dados, se aplicativo, interface ou seja lá o que estiver fazendo, não executar de acordo ao que o negócio exige, estará fadado ao fracasso.
Quem determina o quão rápido o sistema deve ser é o negócio para qual ele será desenvolvido. Por exemplo, em uma aplicação bancária, onde o cliente vai sacar dinheiro, o tempo de operação deve ser menor que 10 segundos após o cliente confirmar a senha. Esse é o requisito para a operação. Entretanto, se o sistema é um fechamento contábil, a operação de fechamento talvez possa esperar 15 minutos por filial.
Certa ocasião, fui chamado para otimizar um sistema em uma concessionária de telecomunicações. O processo batch para bloqueio de terminais pré-pagos estava executando em uma janela de 6 horas. O cliente estava com problemas jurídicos, porque alguns terminais já pagos, eram desbloqueados somente após de 48 horas do pagamento do mesmo. Quando a tarefa do banco de dados foi atribuída a mim, procurei entender o que o processo estava fazendo. Encontrei mais ou menos como segue a tabela/gráfico abaixo:
Podemos notar um overhead de no mínimo 4 horas no processo – MÍNIMO – por que? Ora, se estou na mesma rede, mesma empresa, por que tenho que fazer FTP de um lado para outro? Por que tenho que fazer EXPORT de uma base e IMPORT na outra? Encontrei as respostas facilmente quando investiguei um pouco a origem do sistema. Nenhum analista de banco de dados do lado da nossa empresa, tampouco o DBA da concessionária fora consultado.
Tiradas essas conclusões, armei um plano para desenvolver uma pequena API usando DBLINK, evitando o EXPORT – FTP – IMPORT, ou seja, 4 horas somente em processos desnecessários. Entrei em contato com o DBA deles, acertamos o DBLINK e as permissões necessárias e depois reescrevi o código para desbloqueio a cada N horas conforme o operador determinava; deixei o sistema bastante flexível quanto à execução. Cada vez que o processo “acorda” executava em menos de um minuto e alimentava o MAINFRAME para designar o desbloqueio no mesmo dia. Na verdade, a grande sacada aqui foi: 75% do tempo era gasto em overhead. O que fiz? Me livrei dos processos. Negociei com o DBA para evitarmos esse desperdício. Isso nos rendeu um elegante e-mail de elogios.
Para Performance não existe uma receita de bolo, é preciso usar a criatividade encontrando alternativas. O que é certo é que seu sistema precisa dar SHOW! Precisa de performance SEMPRE.
Labels: Training
Estatísticas, Quando Começar?
Marcio, boa tarde.
Dei uma olhada em seus textos e achei muito interessante, principalmente
os que falam sobre performance.
Gostaria de saber sua opinião em relação a qual momento devemos começar
a utilizar estatísticas, ou, se isso é muito relativo e depende muito de
cada aplicação.
Desde já agradeço.
O momento de começar a usar as estatísticas, em minha opinião, é na concepção do sistema. Quando voce estiver desenhando suas tabelas físicas já terá subsídio suficiente para decidir o size do histograma, particionamento, volumetria, índices, PK, FK, UK, constraints, not null, FBI, MV, etc. Toda essa gama de instrução é levada em consideração. Portanto quanto mais informação for passada ao Oracle em forma de regras de negócio (pk, fk, constraints, índices, etc), mais ele terá chance de decidir corretamente sobre como chegar aos dados.
Por outro lado e não menos importante, os fatores globais também influenciarão o otimizador no novo sistema como capacidade de leitura física, quanto do índice será reaproveitado em cache, qual o custo do uso do índice, quanto de espaço os agrupamentos e ordenações irão consumir, quantos usuários simultaneos haverão no sistema, qual disponibilidade de hardware (Disco, CPU e memória), quantas transações serão esperadas por minuto, qual será a estratégia de backup, etc. Para cada uma destas informações, há uma ou mais entradas correspondentes no spfile para compor as estatísticas que irão alimentar o otimizador. Por exemplo: Qual o melhor caminho para chegar ao Aeroporto de Congonhas? Depende! De que? Ora de onde é o ponto de partida. Vê: Tudo depende do quanto se conhece para traçar um plano.
Eu começo desde o desenho, caso haja necessidade de alguma exceção de size ou sample, eu trabalho isso nos defaults (agora podemos customizar os defaults no 10gr2 - pesquise sobre a dbms_stats). Quando o desvio é grande, eu volto para a "prancheta", porque, na maioria da vezes, estou me perdendo no projeto e algo está mal dimencionado ou desenhado. Tento manter tudo o mais simples possível. A partir do primeiro protótipo, pode ter certeza, as tabelas estarão atualizadas e haverá um job coletando estatísticas quando necessário.
Labels: Training
![]()
